부제: javascript 몰라요, c++ 몰라요 bigquery 만 알아요 사람의 udf 탐험기
글 쓴 계기 : 반복적이고 귀찮은 작업은 최대한 피하고 자동화를 해보자 싶어, 기존에 지표를 빅쿼리로 분석하고 엑셀로 옮기거나, 파이썬으로 옮겨서 통계적 유의성을 확인하는 작업을 한방에 해보자 싶어서 udf 를 이용하게 되었습니다. 처음 만들고 나니 너무 간편하여 다른 것도 만들어보고 싶어졌고 나와 같은 나무늘보 성향의 사람이 이 글을 보고 귀찮은 작업을 줄일 수 있으면 좋겠다! 싶어서 쓰게 되었습니다. udf 의 대한 글이었지만 udf 에서 단순히 하나의 값만 나오는게 아니라 테이블을 input으로 바로 넣고 output으로 또 다른 테이블로 출력도 되게 하는 형태를 알게 되었고 이것이 유용하다 생각하여 이를 위한 array와 struct 에 대한 설명도 featuring 정도로 곁들였습니다.
이 글은,
1. udf 에 대한 기본 설명과 사용법
2. array, struct 를 이용하여 udf에 여러 컬럼을 한번에 출력하는 방법 (+array, struct 간략 설명)
으로 이루어져 있습니다.
udf 란 무엇인가
udf(user-defined function)란 사용자 정의 함수. 즉, 내가 만들어 사용하는 함수이기에 반복된 작업을 함수화 시켜놓으면 시간 절약, 쿼리도 절약됩니다. 쓰고 싶은 용도에 따라 두가지로 나뉩니다.
- 이 쿼리문에서만 잠깐 쓰겠다 → temp udf
- bigquery dataset에 저장해 다른 쿼리문에서도 불러와 계속 쓰고싶다 → persistent UDF
udf 사용법
생성하기
Temp udf 생성
CREATE [OR REPLACE] {TEMPORARY | TEMP} FUNCTION [IF NOT EXISTS] function_name ([named_parameter[, ...]])
[RETURNS data_type]
{ sql_function_definition | javascript_function_definition }
위는 빅쿼리 공식문서에서 가져온거고 좀 간단하게 가보자면
CREATE TEMP FUNCTION 함수이름명명 (함수input인자이름 데이터타입 (갯수 상관 없음))
RETURNS 출력될 데이터 타입
AS (함수 정의) ;
의 형태라고 생각하시면 됩니다.
- 함수 인자를 지정할 때는 이름과 타입이 한 쌍으로 들어가게 됩니다. 데이터 타입은 빅쿼리의 데이터 유형 이고 모든 타입이 가능합니다.
- RETURNS 뒤에도 출력될 데이터 타입을 함께 적어줍니다. 빅쿼리에서는 생략이 가능하나 쓰는걸 추천하며 쓰지 않을 시 빅쿼리는 함수 본문을 통해 데이터 타입을 추론해냅니다.
- 같은 이름의 udf 가 존재할 경우 새로운 정의 작업을 하지 않으려면 FUNCTION 뒤에 'IF NOT EXISTS' 를 추가해줍니다.
- 마지막엔 꼭 ';' 를 붙여줍니다
예시
CREATE TEMP FUNCTION how_many_lines (trinangles int64, rectangle int64)
RETURNS int64
AS (trinangles*3 + rectangle*4);Temp udf 변경
그러나 함수를 지정하고 실수를 발견하거나, 바꾸고 싶을 수 있으니 그럴 땐 CREATE 뒤에 OR REPLACE 를 넣어줍니다. 그리고 변경하고 싶은 부분들을 변경하여 진행하면 됩니다.
CREATE OR REPLACE TEMP FUNCTION 함수이름명명 (함수 input 인자 (갯수 상관 없음))
RETURNS 출력될 데이터 타입
AS {변경할 새로운 함수에 대한 정의}
그러나 임시는 그 쿼리문에서만 쓰고 날아가기에 잘 만든 udf 백번 천번 잘 쓰기 위해선 영구로 만들어주는게 필요합니다. 영구 udf 는 temp 와 문법적 구성이 크게 다르지 않지만, 영구로 해줘야한다는 점에서 어떤 데이터 프로젝트의 데이터셋으로 지정할거냐의 부분만 추가된다 생각하면 됩니다.
Persistent UDF 생성
CREATE [OR REPLACE] FUNCTION [IF NOT EXISTS] [[project_name.]dataset_name.]function_name ([named_parameter[, ...]])
[RETURNS data_type]
{ sql_function_definition | javascript_function_definition }
temp udf 와 다른 점은 'temp' 라는 지칭을 하지 않는다, 함수 이름 앞에 [[project_name.]dataset_name.] 부분이 추가되었다는 것입니다. 데이터 셋 아래에 udf로 추가해준다음 후에 다른 쿼리문에서도 이를 불러와서 쓸 수 있습니다.
- 변경은 temp 와 마찬가지로 이 틀에서 create 뒤에 or replace 만 넣어주면 같은 이름의 udf 를 새롭게 정의 가능합니다.
예시
CREATE FUNTION writingclub_udf.how_many_lines (trinangles int64, rectangle int64)
RETURNS int64
AS (trinangles*3 + rectangle*4)- 위에서 예로 든 함수를 영구 udf 로 만들기.
- 'writingclub_udf. ' 이 추가
- temp가 사라짐
Persistent UDF 삭제
temp 와 달리 그냥 두면 사라지지 않기에 삭제를 하고 싶을 땐 'DROP FUNTION' 뒤에 함수이름
DROP FUNCTION [IF EXISTS] [[project_name.]dataset_name.]function_name예시
DROP FUNCTION writingclub_udf.how_many_lines
UDF output으로 여러 컬럼이 있는 테이블 출력하기
udf 의 경우 여러 input인자를 넣을 수는 있으나,
A SQL UDF can return the value of a scalar subquery. A scalar subquery must select a single column.
단 하나의 컬럼만을 출력해낼 수 있다. 즉, 여러 컬럼을 담은 테이블을 한번에 출력할 수 가 없는 상황.
—> 그렇기에 여러 값들을 하나로 만들어주는 Array 를 이용
But, array는 숫자의 묶음이지 그 숫자에 대한 칼럼명을 함께 정할 수 없다
—> python의 dictionary 처럼(완전히 같은 것이 아니다) Struct 를 이용한다.
Array 와 Struct 간단 지식
Array
:유형이 ARRAY가 아닌 요소가 0개 이상 있는 순서가 지정된 목록
- array 안에는 또 다른 array 를 포함할 수 없다.
선언 방법
1. 대괄호 :
SELECT [1, 2, 3] AS array_sample
2. ARRAY<> :
SELECT ARRAY<INT64>[1,2,3] AS int_array
3. GENERATE 함수:
SELECT GENERATE_ARRAY(1, 21, 3) AS generate_array_data
cf) GENERATE_ARRAY(시작, 종료, 간격)
GENERATE_DATE_ARRAY, GENERATE_TIMESTAMP_ARRAY 등 존재
4. ARRAY_AGG : 테이블에 저장된 데이터를 select 하고 묶고 싶을땐 이 방법을 이용
Struct
:각각 유형(필수)과 필드 이름(선택사항)이 있는 순서가 지정된 필드의 컨테이너
- Array와 달리 값과 키를 설정할 수 있다.
선언 방법
1. 소괄호 :
SELECT (1,2,3) AS struct_test
2. Struct<> :
SELECT STRUCT<INT64, STRING, STRING>(1, 'MATH', 'P') AS struct_1
3. 타입 앞에 이름을 지정 할 수 있음:
SELECT STRUCT<what INT64, which STRING,how STRING>(1, 'MATH', 'P') AS struct_2
4. 타입 지정 안하고, AS 로 이름 지정:
SELECT STRUCT(1 as what, 'MATH' as which, 'P' as how) as struct_3
5. struct 안에 struct :
SELECT STRUCT<struct_4 STRUCT<y INT64, z STRING>>((32, 'P')) AS struct_5
6. array 안에 struct :
ARRAY ( SELECT AS STRUCT) 라는 형태로 사용 (아래 코드에 등장)
예시
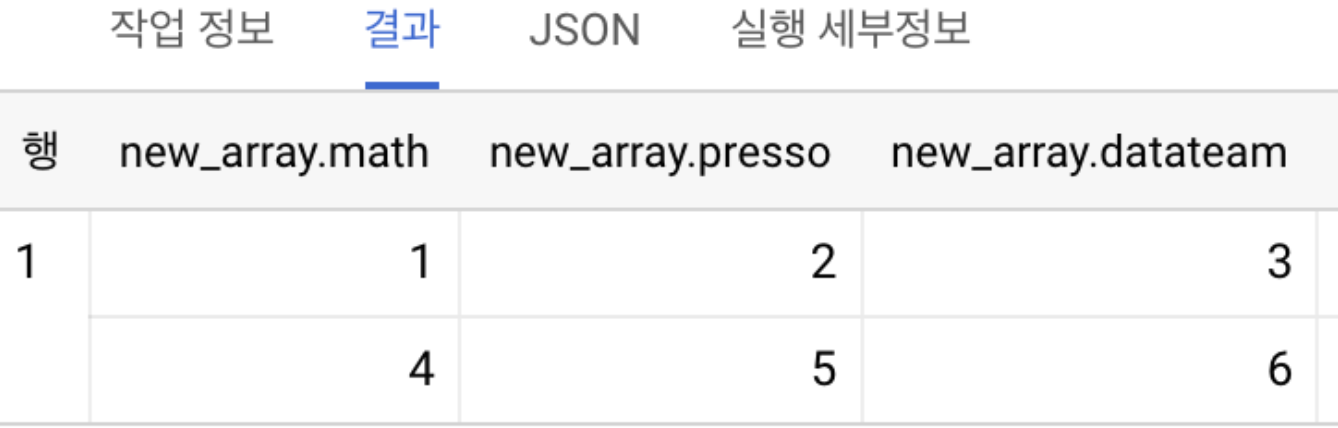
SELECT ARRAY( SELECT AS STRUCT 1 as math, 2 as presso, 3 datateam UNION ALL
SELECT AS STRUCT 4 as math, 5 as presso, 6 datateam ) AS new_array
결과
udf 에서 여러 컬럼의 테이블을 input 으로 넣고, 여러 컬럼의 테이블을 output으로 출력하는 법
방법:
1. A 형태의 테이블을 array of struct 형태로 집어 넣습니다.
2. B 형태의 array of struct 로 output 출력합니다.
3. 해당 array 를 unnest() 하여 각 컬럼에 접근하여 컬럼들을 이용합니다.
예시
udf 목적: 각 실험군 별 전환율을 구하고, 대조군과의 전환율 차이를 구하는 udf



create temp function exp1 (get_table ARRAY<STRUCT <exp_group STRING, n INT64, conversion INT64 >> )
returns ARRAY<STRUCT <exp_group STRING, participants INT64, conversion INT64, rate FLOAT64, diff_rate FLOAT64 >>
as (
array(
select as struct
exp_group, n, conversion, rate, rate-control_rate as rate_diff
from (
select g.exp_group, g.n, g.conversion,
safe_divide(g.conversion, g.n) as rate,
(select g.n from unnest(get_table) g where g.exp_group = 'control') as control_n,
safe_divide((select g.conversion from unnest(get_table) g where g.exp_group = 'control'), (select g.n from unnest(get_table) g where g.exp_group = 'control')) as control_rate
from unnest(get_table) g
)
)
);
사용방법
input :
(get_table ARRAY<STRUCT <exp_group STRING, n INT64, conversion INT64 >> )
array of struct 형태로 각 칼럼 값을 struct 형태로 만든다음, array로 묶어 진행합니다.
→ 따라서 해당 udf 사용시 이와 같은 형태로 맞춰 주어 array_agg(struct ( column1, column2, column3)) 으로 input
exp1( array_agg( struct(user_type, n, conversed) )) as s
returns:
ARRAY<STRUCT <exp_group STRING, participants INT64, conversion INT64, rate FLOAT64, diff_rate FLOAT64 >>
-> output은 array of struct 형태이므로 그래프를 그리기 위해 해당 컬럼들에 접근하고 싶으면 unnest() 를 해줘야 합니다.
어떤 변수로 묶어서 변수별 대조군, 실험군 비교를 하고 싶을 경우 group by 를 이용합니다.
--로케일 별로 대조군,실험군 비교를 해야할 때
with data as (....... )
,last as (
select locale, exp1(
array_agg(
struct(user_type, n, conversed)
)) as s
from data
group by locale
order by locale
)
select locale, exp_group , cvr, participants ,conversions , cvr_diff_percent_point, stat_sig
from last , unnest(s)
C와 같은 결과가 나오는 전체 쿼리
create temp function exp1 (get_table ARRAY<STRUCT <exp_group STRING, n INT64, conversion INT64 >> )
returns ARRAY<STRUCT <exp_group STRING, participants INT64, conversion INT64, rate FLOAT64, diff_rate FLOAT64 >>
as (
array(
select as struct
exp_group, n, conversion, rate, rate-control_rate as rate_diff
from (
select g.exp_group, g.n, g.conversion,
safe_divide(g.conversion, g.n) as rate,
(select g.n from unnest(get_table) g where g.exp_group = 'control') as control_n,
safe_divide((select g.conversion from unnest(get_table) g where g.exp_group = 'control'), (select g.n from unnest(get_table) g where g.exp_group = 'control')) as control_rate
from unnest(get_table) g
)
)
);
with data as (
select
*
from
unnest([
struct('kr' as locale, 'control' as user_type, 260061 as n, 85113 as conversed),
struct('kr' as locale, 'variant1' as user_type, 260014 as n, 85886 as conversed),
struct('kr' as locale, 'variant2' as user_type, 260189 as n, 85792 as conversed),
struct('jp' as locale, 'variant1' as user_type, 169541 as n, 74323 as conversed),
struct('jp' as locale, 'variant2' as user_type, 169320 as n, 74567 as conversed),
struct('jp' as locale, 'control' as user_type, 167495 as n, 73135 as conversed)
])
)
, last as (
select locale, exp1( array_agg(struct(user_type, n, conversed)) ) as s
from data
group by locale
order by locale
)
select locale, s.*
from last, unnest(s) as s
cf) 모비율 차이 검정 통계적 유의성 확인 udf
create temp function exp1 (know_stat_sig ARRAY<STRUCT<exp_group STRING, participants INT64, conversions INT64>>)
returns ARRAY<STRUCT<exp_group STRING, participants INT64, conversions INT64, cvr FLOAT64, cvr_diff_percent_point FLOAT64, stat_sig FLOAT64>>
as (
array(
select as struct
exp_group, participants, conversions, cvr, cvr_diff_p,
case
when exp_group = 'control' then null
else `isb-cgc-bq.functions.jstat_normal_cdf_current`(abs(z), 0.0, 1.0)
end as stat_sig,
from (
select
exp_group, participants, conversions, cvr, cvr-cvr_c as cvr_diff_p,
safe_divide((cvr - cvr_c), sqrt(cvr * (1 - cvr) / participants + cvr_c * (1 - cvr_c) / participants_c)) as z,
if(participants_c is null or cvr_c is null, error('control 데이터가 없습니다.'), null),
from (
select
b.exp_group, b.participants, b.conversions,
safe_divide(b.conversions, b.participants) as cvr,
(select s.participants from unnest(know_stat_sig) s where s.exp_group = 'control') as participants_c,
safe_divide((select s.conversions from unnest(know_stat_sig) s where s.exp_group = 'control'), (select s.participants from unnest(know_stat_sig) s where s.exp_group = 'control')) as cvr_c
from
unnest(know_stat_sig) b
)
)
order by
exp_group
)
);외부 udf 사용
외부에 등록되어 있는 udf 들 또한 이용이 가능합니다.
isb-cgc-bq.functions.jstat_normal_cdf_current(abs(z), 0.0, 1.0)
Returns the value of x in the cdf of the Normal distribution with parameters mean and std.
- Input: x: the value (type FLOAT64), mean (type FLOAT64), and std: standard deviation (type FLOAT64).
- Output: the cdf of the normal distribution
isb-cgc-bq.functions.kmeans_current(PointSet, 100, 3)
Estimates cluster assigments using the K-means algorithm (https://en.wikipedia.org/wiki/K-means_clustering), implemented in JavaScript.
- Input: DataPoints: data points in the form of an array of structures where each element is an array that represents a data point (type ARRAY<STRUCT<point ARRAY>>), iterations: the number of iterations (type INT64), and k: the number of clusters (type INT64).
- Output: An array of labels (integer numbers) representing the cluster assigments for each data poin
Reference
https://github.com/isb-cgc/Community-Notebooks/tree/master/BQUserFunctions
https://zzsza.github.io/gcp/2020/04/12/bigquery-unnest-array-struct/
https://medium.com/google-cloud/how-to-work-with-array-and-structs-in-bigquery-9c0a2ea584a6
https://cloud.google.com/bigquery/docs/reference/standard-sql/user-defined-functions?hl=ko
'SQL (Google Bigquery)' 카테고리의 다른 글
| [SQL / Bigquery] DATE TYPE 날짜 데이터를 STRING TYPE( 문자열) 으로 변환 하는 법 + 그 반대로도 변환 하는 법 (0) | 2022.07.24 |
|---|